数据库范式
范式的级别
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。
范式越高,冗余最低,一般到三范式,再往上,表越多,可能导致查询效率下降。所以有时为了提高运行效率,可以让数据冗余(反三范式,一般某个数据经常被访问时,比如数据表里存放了语文数学英语成绩,但是如果在某个时间经常要得到它的总分,每次都要进行计算会降低性能,可以加上总分这个冗余字段)。
后面的范式是在满足前面范式的基础上,比如满足第二范式的一定满足第一范式。
第一范式(1NF):确保每一列的原子性
如果每一列都是不可再分的最小数据单元,则满足第一范式。
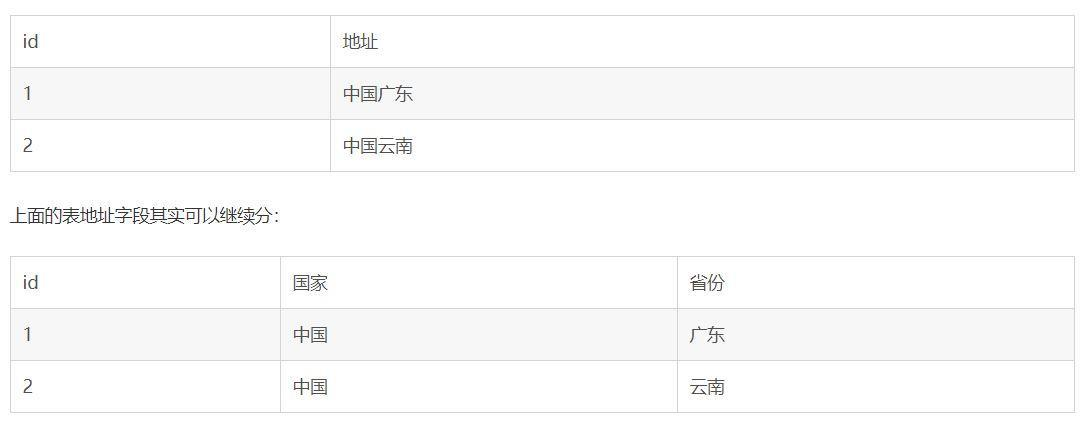
但是具体地址到底要不要拆分 还要看具体情形,比如看看将来会不会按国家或者省市进行分类汇总或者排序,如果需要,最好就拆,如果不需要而仅仅起字符串的作用,可以不拆,操作起来更方便。
第二范式:非键字段必须依赖于键字段
如果一个关系满足1NF,并且除了主键以外的其它列,都依赖与该主键,则满足二范式(2NF),第二范式要求每个表只描述一件事。例如:
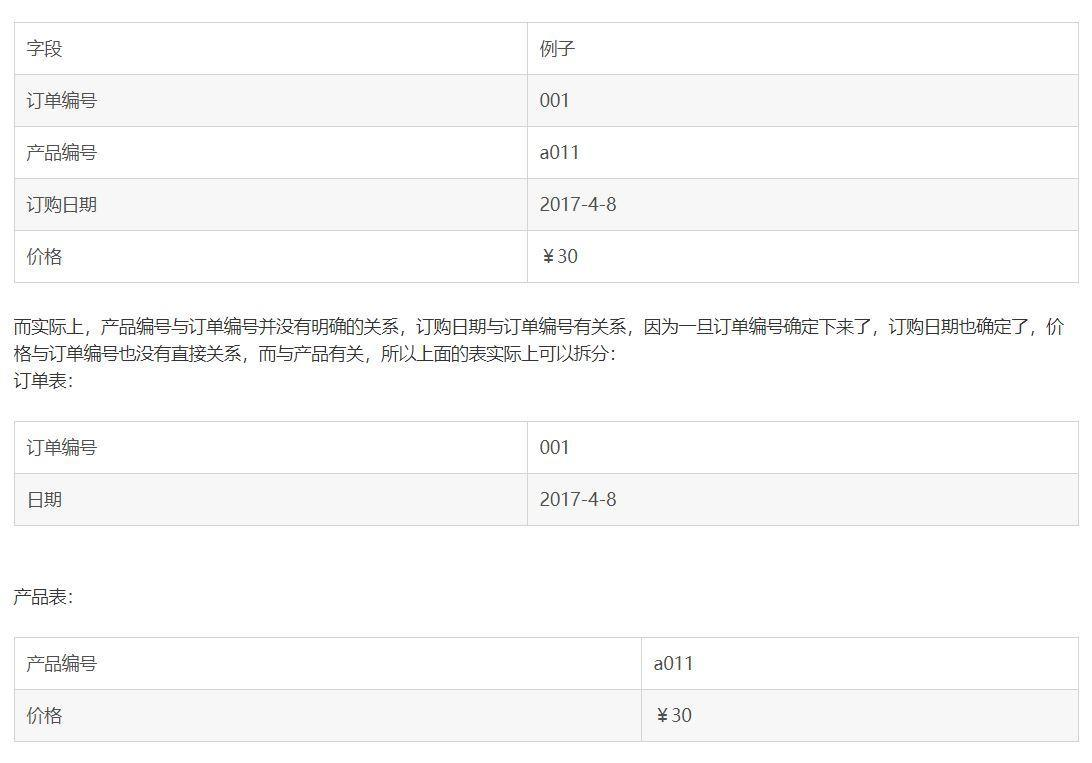
第三范式:在1NF基础上,除了主键以外的其它列都不传递依赖于主键列,或者说: 任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
例如: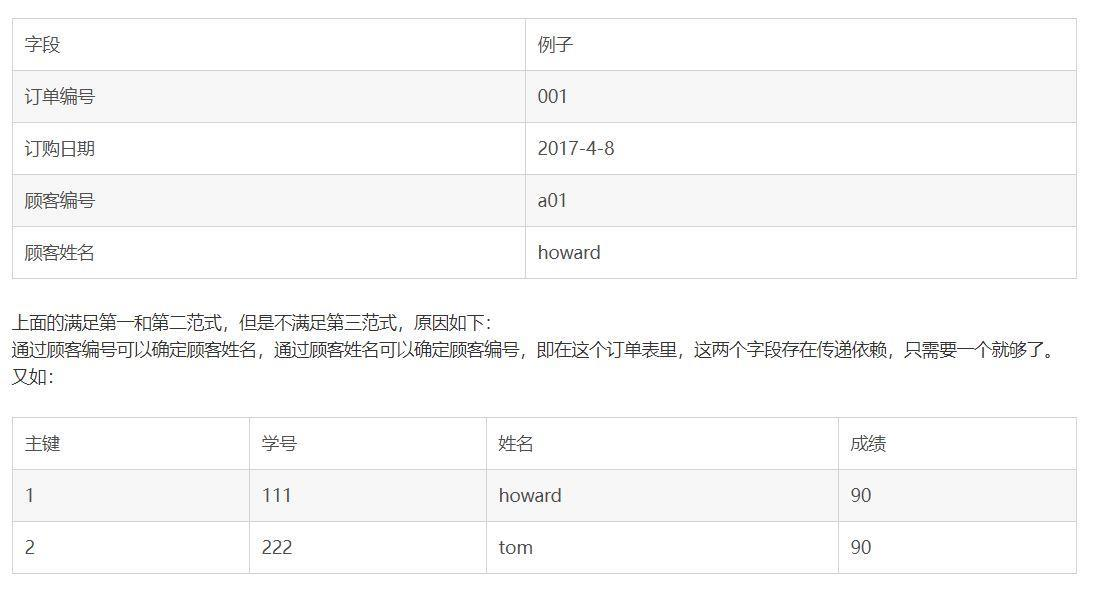
上面的表,学号和姓名存在传递依赖,因为(学号,姓名)->成绩,学号->成绩,姓名->成绩。所以学号和姓名有一个冗余了,只需要保留一个。
范式的优点:
1)范式化的数据库更新起来更加快;
2)范式化之后,只有很少的重复数据,只需要修改更少的数据;
3)范式化的表更小,可以在内存中执行;
4)很少的冗余数据,在查询的时候需要更少的distinct或者group by语句。
范式的缺点:
范式化的表,在查询的时候经常需要很多join关联,增加让查询的代价
反范式的优点:
1)可以避免关联,因为所有的数据几乎都可以在一张表上显示;
2)可以设计有效的索引;
反范式的缺点:
表格内的冗余较多,删除数据时候会造成表有些有用的信息丢失。
所以在设计数据库时,要注意混用范式化和反范式化。
[评论][COMMENTS]