1 InnoDB中的存储结构
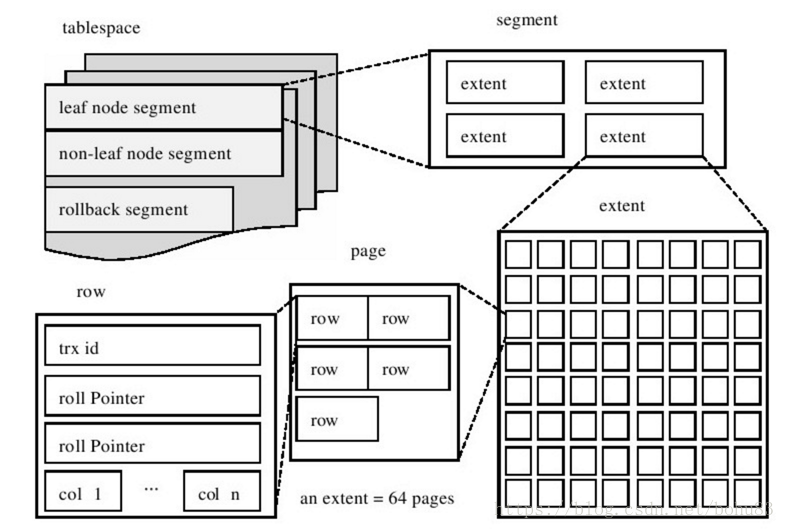
从InnoDB存储引擎的逻辑结构看,所有数据都被逻辑地存放在一个空间内,称为表空间(tablespace),而表空间由段(sengment)、区(extent)、页(page)组成。 在一些文档中extend又称块(block)。
1.1 表空间(table space)
表空间(Tablespace)是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
在 InnoDB 中存在两种表空间的类型:共享表空间和独立表空间。如果是共享表空间就意味着多张表共用一个表空间。如果是独立表空间,就意味着每张表有一个独立的表空间,也就是数据和索引信息都会保存在自己的表空间中。独立的表空间可以在不同的数据库之间进行迁移。可通过命令
mysql > show variables like 'innodb_file_per_table';
查看当前系统启用的表空间类型。目前最新版本已经默认启用独立表空间。
InnoDB把数据保存在表空间内,表空间可以看作是InnoDB存储引擎逻辑结构的最高层。本质上是一个由一个或多个磁盘文件组成的虚拟文件系统。InnoDB用表空间并不只是存储表和索引,还保存了回滚段、双写缓冲区等。
1.2 段(segment)
段(Segment)由一个或多个区组成,区在文件系统是一个连续分配的空间(在 InnoDB 中是连续的 64 个页),不过在段中不要求区与区之间是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当我们创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。
1.3 区块(extent)
在 InnoDB 存储引擎中,一个区会分配 64 个连续的页。因为 InnoDB 中的页大小默认是 16KB,所以一个区的大小是 64*16KB=1MB。在任何情况下每个区大小都为1MB,为了保证页的连续性,InnoDB存储引擎每次从磁盘一次申请4-5个区。默认情况下,InnoDB存储引擎的页大小为16KB,即一个区中有64个连续的页。
1.4 页(Page)
页是InnoDB存储引擎磁盘管理的最小单位,每个页默认16KB;InnoDB存储引擎从1.2.x版本碍事,可以通过参数innodb_page_size将页的大小设置为4K、8K、16K。若设置完成,则所有表中页的大小都为innodb_page_size,不可以再次对其进行修改,除非通过mysqldump导入和导出操作来产生新的库。
innoDB存储引擎中,常见的页类型有:
数据页(B-tree Node)
undo页(undo Log Page)
系统页 (System Page)
事物数据页 (Transaction System Page)
插入缓冲位图页(Insert Buffer Bitmap)
插入缓冲空闲列表页(Insert Buffer Free List)
未压缩的二进制大对象页(Uncompressed BLOB Page)
压缩的二进制大对象页 (compressed BLOB Page)
1.5 行(row)
InnoDB存储引擎是按行进行存放的,每个页存放的行记录也是有硬性定义的,最多允许存放16KB/2-200,即7992行记录。
2 Page详细介绍
2.2 Page完整的结构图
Innodb引擎中的Page完整结构图(注意箭头

可以按下面的分解一下Page的结构:
- 1 各部分描述
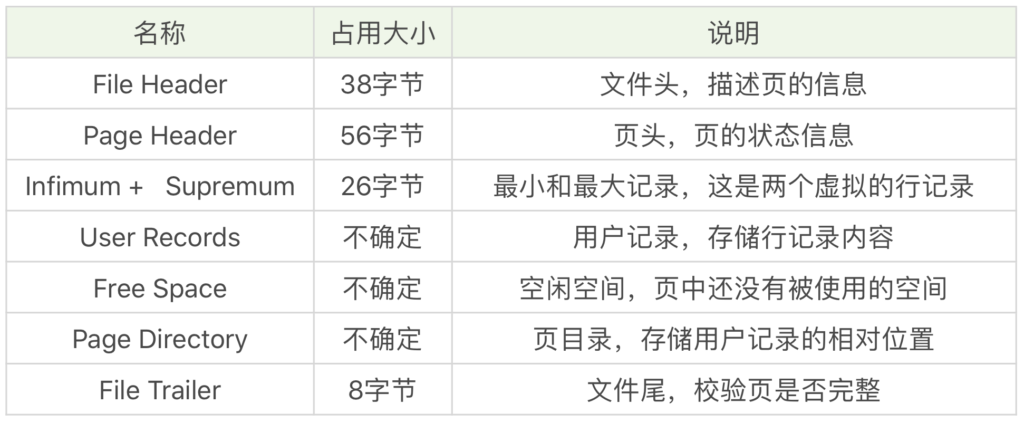
- 2 简单结构图
2.3 Page结构细分
页结构整体上可以分为三大部分,分别为通用部分(文件头、文件尾)、存储记录空间、索引部分。
2.3.1 通用部分
主要指文件头和文件尾,将页的内容进行封装,通过文件头和文件尾校验的CheckSum方式来确保页的传输是完整的。
在文件头中有两个字段,分别是 FIL_PAGE_PREV 和 FIL_PAGE_NEXT,它们的作用相当于指针,分别指向上一个数据页和下一个数据页。连接起来的页相当于一个双向的链表,如下图所示:
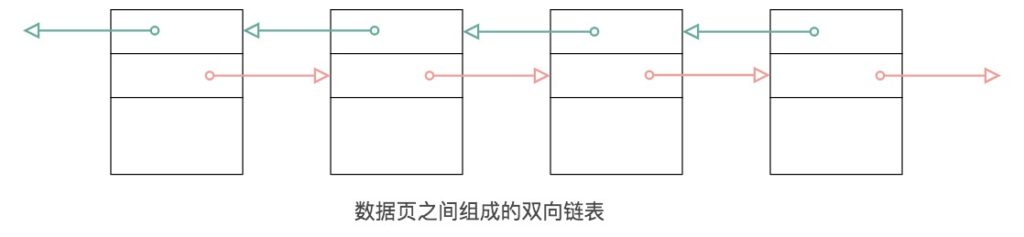
采用链表的结构让数据页之间不需要是物理上的连续,而是逻辑上的连续,物理上的有序,在内存中的地址是连续的,可以进行二分查找,逻辑有序只能遍历,无法二分查找。
2.3.2 第二个部分是记录部分
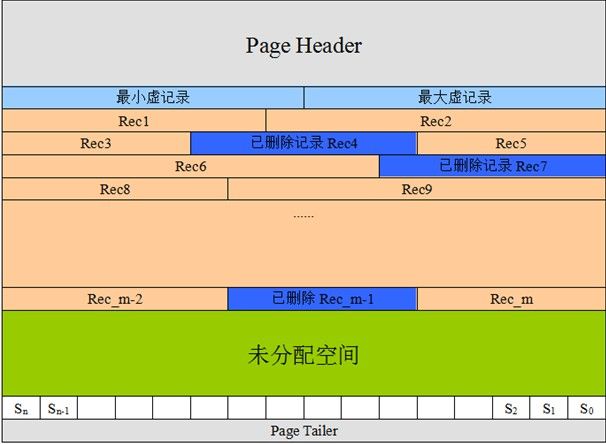
页的主要作用是存储记录,所以“最小和最大记录”和“用户记录”部分占了页结构的主要空间。另外空闲空间是个灵活的部分,当有新的记录插入时,会从空闲空间中进行分配用于存储新记录,如下图所示:
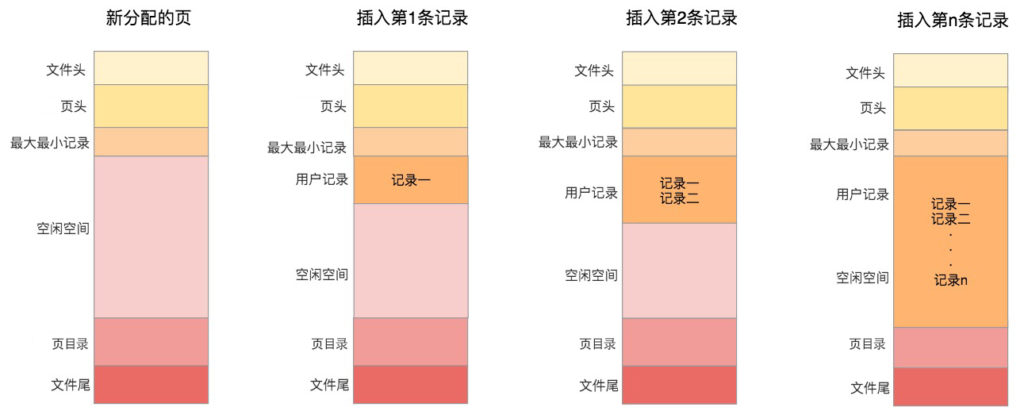
一个页内必须存储2行记录,否则就不是B+tree,而是链表了。
2.3.3 第三部分是索引部分
这部分重点指的是页目录(示意图2中的s0-sn),它起到了记录的索引作用,因为在页中,记录是以单向链表的形式进行存储的。 单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索,因此在页目录中提供了二分查找的方式,用来提高记录的检索效率。 这个过程就好比是给记录创建了一个目录:
将所有的记录分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录。 第 1 组,也就是最小记录所在的分组只有 1 个记录; 最后一组,就是最大记录所在的分组,会有 1-8 条记录; 其余的组记录数量在 4-8 条之间。 这样做的好处是,除了第 1 组(最小记录所在组)以外,其余组的记录数会尽量平分。 在每个组中最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段。 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。如下图所示:
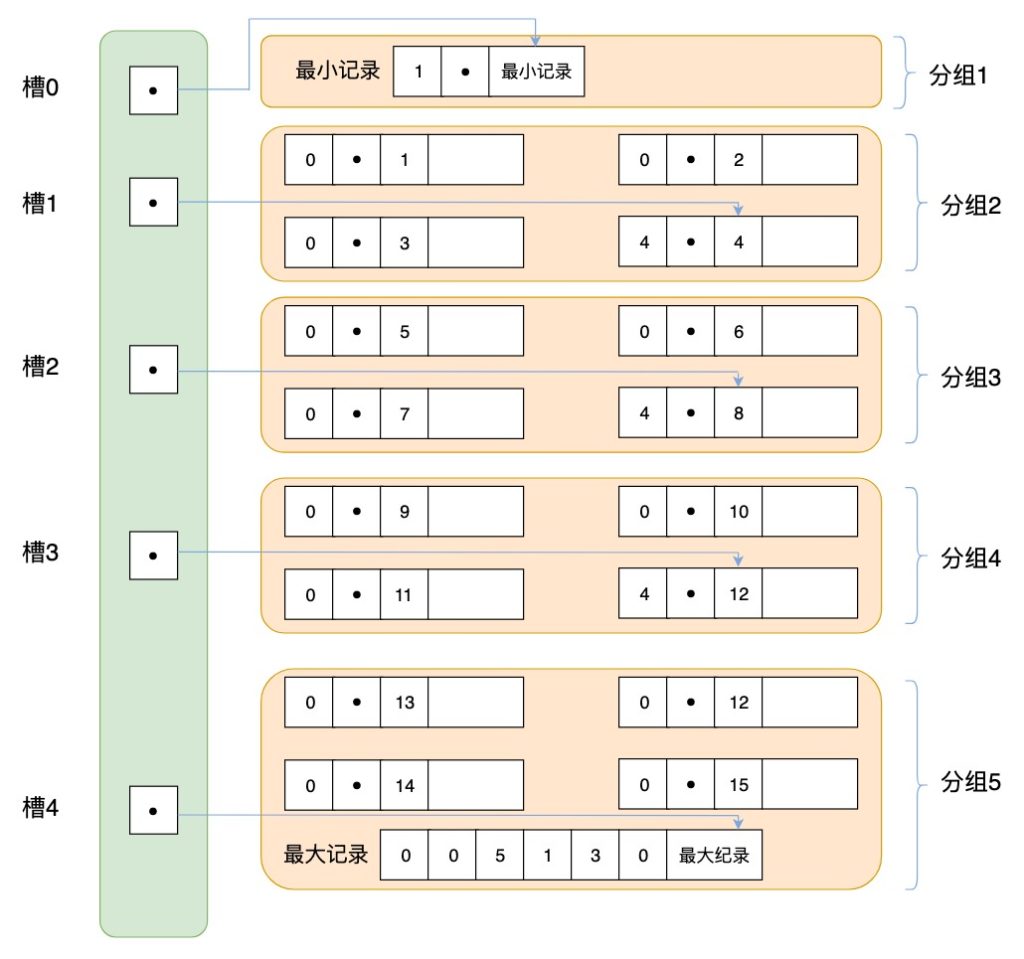
上图基于 槽+单向链表 的方式的搜索和 skiplist 的结构很相似
页目录存储的是槽,槽相当于分组记录的索引。我们通过槽查找记录,实际上就是在做二分查找。这里我以上面的图示进行举例,5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 9 的用户记录,我们初始化查找的槽的下限编号,设置为 low=0,然后设置查找的槽的上限编号 high=4,然后采用二分查找法进行查找。
首先找到槽的中间位置 p=(low+high)/2=(0+4)/2=2,这时我们取编号为 2 的槽对应的分组记录中最大的记录,取出关键字为 8。因为 9 大于 8,所以应该会在槽编号为 (p,high] 的范围进行查找
接着重新计算中间位置 p’=(p+high)/2=(2+4)/2=3,我们查找编号为 3 的槽对应的分组记录中最大的记录,取出关键字为 12。因为 9 小于 12,所以应该在槽 3 中进行查找。
遍历槽 3 中的所有记录,找到关键字为 9 的记录,取出该条记录的信息即为我们想要查找的内容。
2.3.4 B+ 树是如何进行记录检索
如果通过 B+ 树的索引查询行记录,首先是从 B+ 树的根开始,逐层检索,直到找到叶子节点,也就是找到对应的数据页为止,将数据页加载到内存中,页目录中的槽(slot)采用二分查找的方式先找到一个粗略的记录分组,然后再在分组中通过链表遍历的方式查找记录。
[评论][COMMENTS]