1 背景
在分布式项目中,在业务数据中需要生成一个全局唯一的序列号,比如:消息标识,订单标识,用户标识等等。同时对于id生成的要求如下: * 全局唯一 * 趋势有序 * 主键索引 方便排序 * 高可用 * 高并发
2 基础方案
2.1 数据库主键自增
利用mysql的auto_increment特性 >优点: (1)能够保证唯一性 (2)能够保证递增性 (3)步长固定
缺点: (1)无法高可用:普通的一主多从+读写分离架构,自增ID写入请求,主库挂了就GG (2)无法高并发:写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
2.2 UUID
uuid算法是比较常用的算法,根据UUID的特性,可以产生一个唯一的字符串
优点: (1)本地生成ID,无需远程服务调用,低延时 (2)扩展性好,基本可以-认为没有性能上限
缺点: (1)无法保证趋势递增 (2)uuid字符串过长,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性) (3)如使用实现版本的=不一样,在高并发情况下可能会出现UUID重复情况
2.3 时间戳
优点: (1)本地生成ID,无需远程调用,低延时 (2)ID趋势递增 (3)ID是整数,建立索引后查询效率高
缺点: (1)如果并发量超过1000,会生成重复的ID
3 Twitter Snowflake
3.1 简介
snowflake是twitter开源的分布式ID生成算法,其核心思想是:一个long型的ID,使用其中41bit作为毫秒数,10bit作为机器编号,12bit作为毫秒内序列号。这个算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求
3.2 图示详解
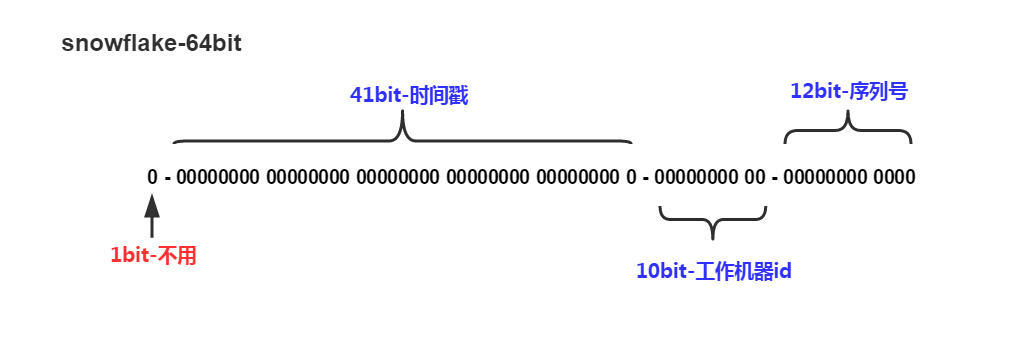
(1)1位:标识部分,在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以为0
(2)41位:时间戳部分,这个是毫秒级的时间,_一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间)_,这样可以使产生的ID从更小值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
(3)10位:节点部分,Twitter实现中使用前5位作为数据中心机房标识,后5位作为单机房机器标识,可以部署1024个节点
(4)12位:序列号部分,支持同一毫秒内同一个节点可以生成4096个ID
SnowFlake算法生成的ID大致上是按照时间递增的,用在分布式系统中,需注意数据中心标识和机器标识必须唯一,这样才能保证每个节点生成的ID都是唯一
3.3 java实现
public class IdWorker {
//idepoch + datacenterId + workerId + sequence
private final long workerId;
private final long datacenterId;
private final long idepoch;
/**
* 前5位作为数据中心机房标识,后5位作为同一机房机器标识
*/
private static final long WORKER_ID_BITS = 5L;
private static final long DATACENTER_ID_BITS = 5L;
private static final long MAX_WORKER_ID = -1L ^ (-1L << WORKER_ID_BITS);
/**
* 单机房最多机器为 1111 1111 ^ 1110 0000 0001 1111
*/
private static final long MAX_DATACENTER_ID = -1L ^ (-1L << DATACENTER_ID_BITS);
/**
* 序列号12位
*/
private static final long SEQUENCE_BITS = 12L;
private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;
private static final long DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
private static final long TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS;
private static final long SEQUENCE_MASK = -1L ^ (-1L << SEQUENCE_BITS);
private long lastTimestamp = -1L;
private long sequence;
private static final Random r = new Random();
public IdWorker() {
this(1344322705519L);
}
public IdWorker(long idepoch) {
this(r.nextInt((int) MAX_WORKER_ID), r.nextInt((int) MAX_DATACENTER_ID), 0, idepoch);
}
public IdWorker(long workerId, long datacenterId, long sequence) {
this(workerId, datacenterId, sequence, 1344322705519L);
}
//
public IdWorker(long workerId, long datacenterId, long sequence, long idepoch) {
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
this.idepoch = idepoch;
if (workerId < 0 || workerId > MAX_WORKER_ID) {
throw new IllegalArgumentException("workerId is illegal: " + workerId);
}
if (datacenterId < 0 || datacenterId > MAX_DATACENTER_ID) {
throw new IllegalArgumentException("datacenterId is illegal: " + workerId);
}
if (idepoch >= System.currentTimeMillis()) {
throw new IllegalArgumentException("idepoch is illegal: " + idepoch);
}
}
public long getDatacenterId() {
return datacenterId;
}
public long getWorkerId() {
return workerId;
}
public long getTime() {
return System.currentTimeMillis();
}
public long getId() {
long id = nextId();
return id;
}
private synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new IllegalStateException("Clock moved backwards.");
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
long id = ((timestamp - idepoch) << TIMESTAMP_LEFT_SHIFT)
| (datacenterId << DATACENTER_ID_SHIFT)//
| (workerId << WORKER_ID_SHIFT)//
| sequence;
return id;
}
/**
* get the timestamp (millis second) of id
* @param id the nextId
* @return the timestamp of id
*/
public long getIdTimestamp(long id){
return idepoch + (id >> TIMESTAMP_LEFT_SHIFT);
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("IdWorker{");
sb.append("workerId=").append(workerId);
sb.append(", datacenterId=").append(datacenterId);
sb.append(", idepoch=").append(idepoch);
sb.append(", lastTimestamp=").append(lastTimestamp);
sb.append(", sequence=").append(sequence);
sb.append('}');
return sb.toString();
}
public static void main(String[] args) {
IdWorker worker = new IdWorker(2);
System.out.println(worker.nextId());
System.out.println(worker.toString());
System.out.println(worker.nextId());
System.out.println(worker.toString());
}
}
运行main方法结果如下
6414116920725520384
IdWorker{workerId=12, datacenterId=21, idepoch=2, lastTimestamp=1529244642432, sequence=0}
6414116920729714688
IdWorker{workerId=12, datacenterId=21, idepoch=2, lastTimestamp=1529244642433, sequence=0}
得到两个二进制是64位的十进制整数
3.4 优缺点
这样设计的64bit标识,可以保证: (1)每个业务线、每个机房、每个机器生成的ID都是不同的 (2)同一个机器,每个毫秒内生成的ID都是不同的 (3)同一个机器,同一个毫秒内,以序列号区区分保证生成的ID是不同的 (4)将毫秒数放在最高位,保证生成的ID是趋势递增的
缺点 (1)由于“没有一个全局时钟”,每台服务器分配的ID是绝对递增的,但从全局看,生成的ID只是趋势递增的(有些服务器时间早,有些服务器的时间晚) (2)如ID作为取模分库分表的依据,为了分库分表后数据均匀,ID生成往往有“取模随机性”的需求,所以通常把每秒内的序列号放在ID的最末位,保证生成的ID随机,否则取模会不均匀
3.5 雪花算法第三方库
baidu / uid-generator cloudatee/vesta-id-generator
[评论][COMMENTS]