1 Redis的Flicker方案
利用redis的lua脚本功能,在每个节点上通过lua脚本生成唯一ID,生成的ID为64位,具体如下:
使用41 bit来存放时间,精确到毫秒,可以使用到2039年 使用12 bit来存放逻辑分片ID,最大分片ID是4095 使用10 bit来存放自增长ID,则每个节点,每毫秒最多可生成1024个ID 比如GTM时间 2018年6月24日11点23分 ,它的距1970年的毫秒数是 1529810591000,假定分片ID是60,自增长序列是20,则生成的ID是:
6416490681073670164 = 1529810591000 << 22 | 60 << 10 | 20
redis提供了TIME命令,取得redis服务器的秒值和微秒值
毫秒值获取命令:EVAL "local current = redis.call('TIME') ;return a[1]*1000 + a[2]/1000" 0
生成最终ID : current << (12 + 10)) | (shardingId << 10) | seq
2 ID原子性自增方案
2.1 Redis HINCRBY 命令
Redis 的 INCR 命令支持 “INCR AND GET” 原子操作。利用这个特性,我们可以在 Redis 中存序列号,让分布式环境中多个取号服务在 Redis 中通过 INCR 命令来实现取号;同时 Redis 是单进程单线程架构,不会因为多个取号方的 INCR 命令导致取号重复。因此,基于 Redis 的 INCR 命令实现序列号的生成基本能满足全局唯一与单调递增的特性,并且性能还不错。
实际上,为了存储序列号的更多相关信息,我们使用了 Redis 的 Hash 数据结构,Redis 同样为 Hash 提供 HINCRBY 命令来实现 “INCR AND GET” 原子操作。
2.2 Redis宕机问题
Redis 在提供高性能存取的同时,支持*RDB 和 AOF 持久化*,来保证宕机后的数据恢复:
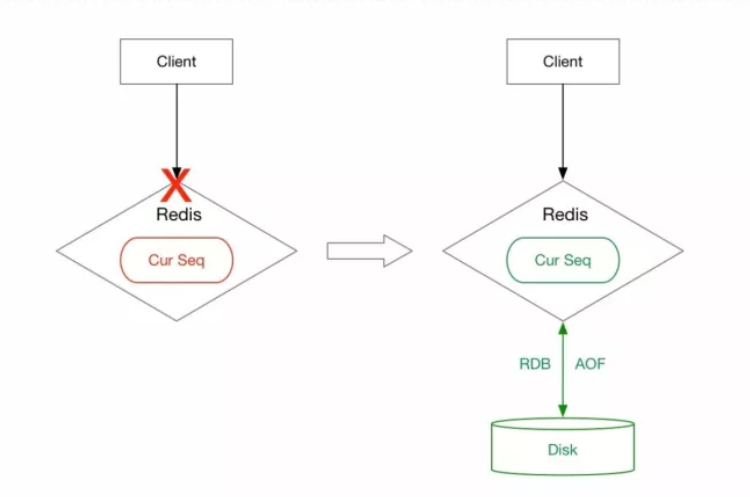
- 如果开启 RDB 持久化,由于最近一次快照时间和最新一条 HINCRBY 命令的时间有可能存在时间差,宕机后通过 RDB 快照恢复数据集会发生取号重复的情况
- 如果使用 AOF 持久化,通过追加写命令到 AOF 文件的方式记录所有 Redis 服务器的写命令,不会发生取号重复的情况。但 AOF 持久化会损耗性能并且在宕机重启后可能由于文件过大导致恢复数据时间过长,并且通过 AOF 重写来压缩文件,在写 AOF 时发生宕机导致文件出错,则需要较多时间去人为恢复 AOF 文件
2.3 宕机恢复方案
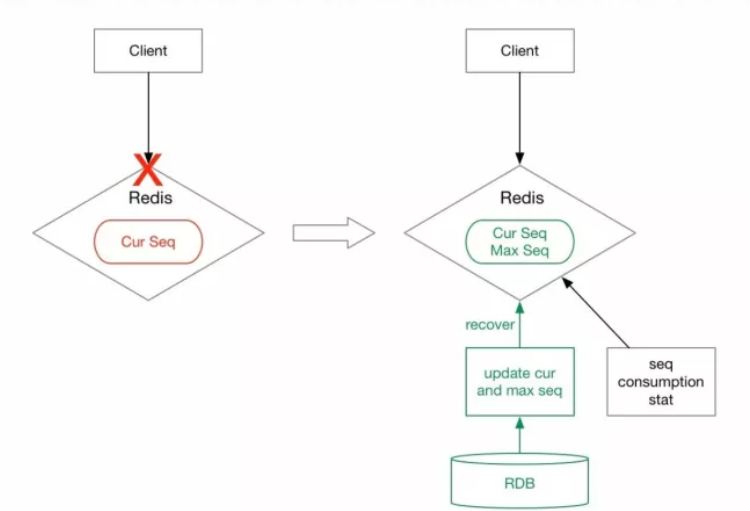
利用mysql记录最大序列号 max,然后设计一个服务定期统计序列号消费速度,当 Redis 中当前可取序列号接近 max 时自动更新 max 到一个适当的值,存入数据库和 Redis。在 Redis 宕机的情况下,将从数据库拉取最大值复成 Redis 当前已取序列号,防止 Redis 取号重复。当然,mysql也可能发生宕机,不过由于取号操作在 Redis,可增加最大可取序列号来提供足够时间恢复mysql
数据预热伪代码:
@Component
@Order(value = 1)
public class CacheRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
//doSomething
System.out.println("==================id预加载=======================");
}
}
通过实现CommandLineRunner的方式,完成数据的预加载,宕机重启,可通过后台服务刷新redis可用最大值来解决
2.3 Redis设计
i 数据结构
采用原子性hash,具体设计如下:
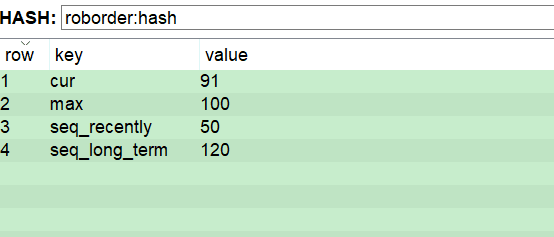
其中 cur 表示当前游标位置,即最新生成的序列号id max 表示当前情况下允许生成的最大序列号 seq_recently 统计5分钟消耗的id数量 seq_long_term 统计30分钟内消耗的id数量
ii Redis调用分析
通过 HINCRBY 命令生成ID并且取出,然后校验当前值是否超出了最大可用序列号 max。seqs_recently 和 seqs_long_term 记录了当前序列消耗的序列号数,用于计算之后增大 max 的步长,即扩容算法。具体生成id代码如下:
public static long hashIncrementAndGetNumber(final String key, final List<String> fields) {
Jedis jedis = null;
try {
jedis = getJedis();
String script =
"local maxSeqNumStr = redis.pcall('HGET', KEYS[1], ARGV[1]) "
+"if type(maxSeqNumStr) == 'boolean' and maxSeqNumStr == false then return nil end "+
"local maxSeqNum = tonumber(maxSeqNumStr) "
+ "local seqNum = redis.pcall('HINCRBY', KEYS[1], ARGV[2], ARGV[3]) "
+ "if seqNum <= maxSeqNum then "
+ " return seqNum else return nil end";
Object result = jedis.eval(script, Collections.singletonList(key), fields);
return (long) result;
} catch (Exception e) {
logger.error("releaseRedisLock error : " + e);
return -1L;
}finally {
recycleJedisOjbect(jedis);
}
}
通过 hashIncrementAndGetNumber("roborder:hash", Arrays.asList("max", "cur", "1"));获取值,自增步幅 +1
2.4 Mysql设计
mysql表设计无需赘述
CREATE TABLE `id_generator` (
`id` int(10) NOT NULL,
`current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
`increment_step` int(10) NOT NULL COMMENT '步幅长度',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
通过定时任务计算max服务,根据 seqs_recently 和 seqs_long_term,预估之后一小时所需要消耗的序列号数。如果当前剩余序列号数不足以支撑十五分钟,则扩容计算之后一小时将消耗的序列号数作为步长,更新 max 到 MySql 和 Redis,保证客户端应用每次能获取到有效的序列号
当然,如果还未来得及计算序列号的消耗,而序列号的使用已达到可用序列号的最大值,可利用fail-fast 机制,提示异常,防止线程阻塞带来的问题
[评论][COMMENTS]